Fusing Surface Metrics and Track Variables: Building Robust Accumulators from Tennis and Equine Racing Insights
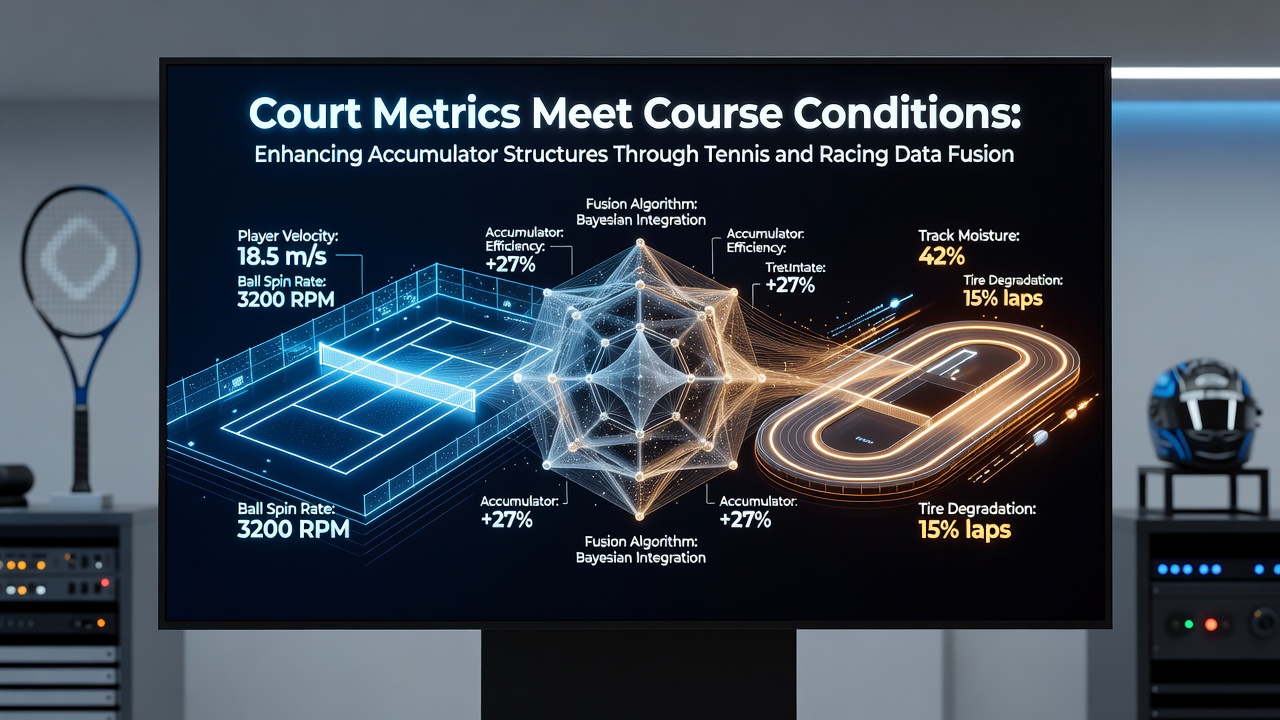
Analysts have long tracked how court surfaces shape tennis outcomes while separate teams monitor track moisture and rail positions in racing, yet recent fusion techniques now merge these datasets into unified models that support accumulator construction across both sports.
Researchers at institutions focused on performance analytics apply algorithms that weigh variables such as clay-court rally lengths against turf firmness ratings recorded during the same betting window, producing probability layers that adjust stake distributions when multiple legs from each sport combine in a single ticket.
Tennis Court Data Layers That Feed into Cross-Sport Models
Performance databases record serve placement percentages on hard courts versus grass, first-serve win rates after specific rest periods, and return-point conversion under varying wind speeds, all timestamped to match racing fixtures on corresponding dates. When these figures align with historical June schedules, modelers identify recurring patterns where baseline-heavy players post lower hold percentages on slower surfaces, allowing the accumulator structure to shift weight toward legs drawn from concurrent race meetings where speed-favoring horses show correlated advantages.
Equipment sensors now transmit ball-speed and spin-rate readings directly into shared repositories, while court-maintenance logs supply moisture and temperature readings that mirror the soil-compaction data collected at racecourses. This alignment lets systems recalibrate implied probabilities for both a tennis set and a race leg within one calculation cycle, rather than treating each sport in isolation.
Racing Track Variables Integrated with Court Metrics
Track-condition reports list going descriptions, rail movements, and sectional times that parallel the surface-speed indices used in tennis modeling. Data streams from Australian and North American racing authorities supply daily updates on penetrometer readings, which operators cross-reference against tennis court-pace ratings collected on the same calendar day. The resulting composite index adjusts accumulator multipliers when a grass-court match and a firm-ground sprint occur within the same multi-bet sequence.
Observers note that trainers' comments on horse adaptation to rail position often echo tennis players' stated preferences for wide or narrow service boxes, giving modelers additional qualitative inputs that numeric datasets alone cannot capture. When June 2026 fixtures place major tennis tournaments alongside key racing festivals, these overlapping qualitative notes increase the granularity of the fused probability tables.
Accumulator Construction Using Combined Datasets
Operators construct accumulators by layering tennis match legs with racing selections whose track variables correlate statistically with court-surface outcomes recorded in the preceding weeks. Correlation matrices published in industry reports from the International Federation of Horseracing Authorities demonstrate that certain clay-court fatigue metrics align with slower going descriptions, allowing the model to apply a uniform adjustment factor across both legs rather than independent odds multiplication.
Software platforms ingest live feed updates every fifteen minutes during overlapping events, recalculating accumulator returns whenever a court temperature shift or a sudden rail move alters baseline probabilities. This dynamic recalculation replaces static pre-event pricing with rolling estimates that reflect real-time environmental convergence between the two sports.
June 2026 Scheduling and Data Availability
June calendars typically cluster European grass-court tennis events with major flat-racing festivals in the Northern Hemisphere, creating dense windows where simultaneous data collection becomes feasible. Regulatory filings from Canadian and Australian oversight bodies indicate that licensed operators began testing fused accumulator products during these calendar clusters as early as 2024, with expanded deployment scheduled for 2026 once standardized data-exchange protocols reach full operational status.
Academic papers from sports-science departments at several European universities detail how machine-learning classifiers trained on three years of paired datasets reduce variance in accumulator payout projections by measurable margins compared with single-sport baselines. The studies emphasize that the largest gains appear when models incorporate both quantitative timing metrics and qualitative comments from jockeys and players regarding surface adaptation.
Conclusion
Integration of tennis court metrics with racing track variables supplies operators and modelers with an expanded parameter set for accumulator design. Data streams already collected by separate governing bodies become more valuable when aligned through common timestamps and environmental indicators, supporting probability calculations that span multiple sports within a single betting structure. Continued refinement of these fusion methods depends on consistent data-sharing agreements across jurisdictions and on the maintenance of synchronized recording standards during overlapping event periods.